


I. Introduction▲
Ce tutoriel a pour but de présenter l'architecture d'une application web Java EE basée sur Hibernate/JPA, Spring et Tapestry5. Il permettra aussi de mettre en place l'architecture d'une telle application en développant une application exemple de bout en bout.
Nous présenterons donc dans un premier temps le principe des architectures en couches et les frameworks utilisés. Nous construirons ensuite pas à pas une application qui nous permettra de mettre en œuvre les technologies exposées en nous attardant sur les frameworks concernés et chacune des couches développées :
- couche d'accès aux données ;
- couche de services ;
- couche de présentation.
I-A. Architecture 3-tiers▲
I-A-1. Principe des architectures en couches▲
Le principe des couches applicatives repose sur le fait que chaque couche ne traite de manière autonome qu'une partie bien précise du système, un ensemble de fonctionnalités bien définies dans un cadre de responsabilités restreint. Cela contribue à diviser un problème global complexe en une suite de petits problèmes simples et permet une résolution plus facile, plus structurée et plus pérenne de l'ensemble. Ainsi la couche d'accès aux données sera en charge des opérations de lecture/écriture depuis ou vers des sources de données externes diverses ; la couche de services (ou couche métier) fournira quant à elle la logique métier, etc.
Chacune des couches publie ensuite ses services spécialisés à destination d'une autre couche du système de niveau supérieur. Chaque couche se concentre donc sur ses préoccupations propres (accès aux données, logique métier, présentation, etc.) et fait appel à une ou plusieurs couches de niveau inférieur lorsqu'elle sort de sa sphère de responsabilités.
La séparation stricte des couches garantit la séparation des préoccupations et permet de rendre le système plus flexible, plus évolutif, plus robuste et plus maintenable. Ainsi, la couche d'accès aux données peut évoluer (changement de SGBD, fichiers XML, etc.) indépendamment des couches qui l'utilisent puisque ces dernières ne connaissent que la structure et la nature des fonctionnalités publiées par cette couche qui doivent être immuables et non leur implémentation qui est changeante.
La mise en œuvre d'une telle architecture en Java se fait par l'utilisation des mécanismes d'interfaces/implémentations. Chaque couche est ainsi composée d'interfaces qui publient un certain nombre de fonctionnalités et de services et de classes concrètes qui implémentent ces interfaces (et offrent réellement le service publié). Les couches supérieures travaillent ainsi uniquement sur les interfaces qui représentent des contrats immuables entre les deux couches et n'ont aucune connaissance des implémentations. Celles-ci peuvent donc changer sans impacter aucunement les couches qui utilisent le service. La seule contrainte étant le respect strict du contrat défini dans l'interface.
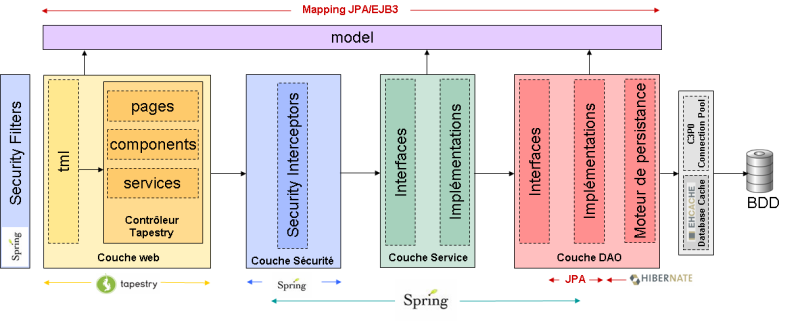
I-A-2. Couche model▲
Rôle
Cette couche représente le modèle de données objet de l'application. C'est une couche particulière car transverse à toute l'architecture puisqu'elle permet en effet de faire correspondre au modèle BDD le modèle objet que l'on va utiliser dans l'application pour manipuler les entités métier. Chaque couche peut donc naturellement manipuler les différentes entités métier représentées par une hiérarchie de JavaBean correspondant chacun à une entité relationnelle. Inversement, cette couche model n'a de visibilité sur aucune autre couche de l'application.
Cette couche représente donc un modèle d'objets et non un ensemble de services et n'est pas construite sous la forme d'interfaces/implémentations, mais comme une hiérarchie de classes concrètes. Les éléments de cette couche sont tous des Value Objects ; c'est-à-dire de simples Beans java (POJO) composés de champs, de getters et de setters.
N.B. Ce sont les objets de cette couche qui sont persistés en base de données par un moteur de persistance: chaque objet (ou presque) est la représentation objet d'un élément ou d'un ensemble d'éléments relationnels (dans le cas d'un SGBDR). Dans notre cas, le moteur de persistance est Hibernate, mais il est masqué par JPA, implémentation du standard de persistance EJB3. C'est donc grâce à la syntaxe EJB3 que nous définirons le mapping à effectuer.
Packages
- <domaine_client>.<nom_client>.<nom_application>.domain.model
I-A-3. Couche DAO (Data Access Object)▲
Rôle
Cette couche est en charge de la gestion des relations avec les sources de données, quelles qu'elles soient. Elle offre des services d'accès, de recherche, de création, de mise à jour, de suppression de données stockées dans un format quelconque (SGBD, LDAP, XML, etc.).
Cette couche d'accès aux objets s'appuie sur une interface standard : JPA (Java Persistence API) permettant de masquer l'implémentation réelle du moteur de persistance : Hibernate. L'utilisation de cette API standard nous permet, une fois de plus, de limiter au maximum l'adhérence du projet à un framework ou à un éditeur tout en conservant l'usage de ses fonctionnalités les plus avancées.
Les mécanismes de persistance permettent d'effectuer les mises à jour courantes simples directement et de manière transparente dans la couche de services : tout objet persistant modifié dans la couche de services transactionnels sera persisté en base.
Packages
- <domaine_client>.<nom_client>.<nom_application>.domain.dao -> Interfaces
- <domaine_client>.<nom_client>.<nom_application>.domain.jpa -> Implémentations en JPQL
N.B. Lorsque plusieurs sources de données fonctionnellement distinctes sont appelées à intervenir dans une même application (une base de données dédiée et un annuaire d'entreprise par exemple), on doit séparer explicitement les implémentations, mais décrire les interfaces au même endroit.
Ainsi les accès à la BDD dédiée seront gérés dans les packages ci-dessus et les accès à un annuaire LDAP d'entreprise dans une sous-couche dédiée.
Par exemple :
- <domaine_client>.<nom_client>.<nom_application>.domain.dao ;
- <domaine_client>.<nom_client>.<nom_application>.domain.dao.ldap.
Par convention, dans une couche dao, les packages d'implémentation font apparaître la technologie utilisée (jpa, ldap, etc.).
I-A-4. Couche Services▲
Rôle
Cette couche implémente l'ensemble de la logique métier de l'application, indifféremment des sources de données utilisées et de la présentation. Elle s'appuie sur les couches DAO et model pour effectuer des opérations CRUD (Create, Research, Update, Delete) sur des objets persistés et leur appliquer ensuite des traitements métier.
D'autre part, cette couche est responsable des aspects transverses : sécurité, transactions. Elle déclare et gère l'ensemble des processus transactionnels vers la couche DAO (l'échec de telle opération de suppression doit annuler telle opération d'insertion précédemment effectuée, etc.). Tout comme la couche DAO, cette couche est composée uniquement de managers (toutes les classes et interfaces sont suffixées par Manager) ; c'est-à-dire de traitements ThreadSafe implémentés par des Singletons (une seule instance partagée).
Le caractère ThreadSafe ainsi que les aspects transactionnels sont gérés par l'utilisation du framework Spring. C'est également l'utilisation de ce framework qui permet réellement de séparer les couches entre elles en réduisant au maximum le couplage entre les différents éléments.
À noter qu'en fonction de la complexité des règles, une couche dédiée à la sécurité peut être mise en place devant la couche de services (entre la couche Présentation et la couche Services).
Packages
- <domaine_client>.<nom_client>.<nom_application>.service
- <domaine_client>.<nom_client>.<nom_application>.service.impl
I-A-5. Couche Front (Présentation)▲
Rôle
Cette couche prend en charge l'ensemble des opérations visant à transformer le résultat brut issu de la couche de services pour offrir une vue particulière des données à l'utilisateur. Il s'agit de contrôleurs Java dont la dépendance avec les autres couches est gérée par Spring. C'est cette couche qui transformera les données de manière à les afficher dans un navigateur web par l'intermédiaire d'un framework.
En l'occurrence, nous travaillons avec le framework Tapestry5.
Packages
- <domaine_client>.<nom_client>.<nom_application>.web
- <domaine_client>.<nom_client>.<nom_application>.web.pages
I-A-6. Couche de Sécurité▲
Security Interceptors : Il s'agit d'une couche dédiée à la sécurité composée de classes Java chargées de vérifier l'authentification et les autorisations d'accès aux méthodes. Ces classes seront automatiquement sollicitées lors de l'appel à une méthode protégée et décideront de laisser passer la requête ou non en fonction des informations de sécurité qui leur sont fournies et de celles dont elles ont besoin.
Security Filters : Il s'agit d'une simple configuration permettant d'autoriser ou non l'accès à certaines pages en fonction de l'identité du demandeur et de ses éventuelles autorisations.
Packages
- <domaine_client>.<nom_client>.<nom_application>.security
Dans cette architecture en couches, chaque couche de niveau n ne peut accéder qu'à la couche model et au contrat de service publié par la couche de niveau n-1.
Cela signifie que la couche front ne peut accéder qu'à la couche model et la couche services, etc. Le contrat de service correspond aux interfaces uniquement. Ainsi chaque couche ne travaillera que sur les interfaces de la couche inférieure en ignorant totalement les implémentations garantissant ainsi une évolutivité maximale.
I-B. Frameworks▲
Pourquoi des Frameworks ? Simplement pour produire des applications professionnelles et sécurisées, pour faciliter les développements et leur fournir un contexte. Ce qui va donc faciliter le travail d'équipe, accroître la productivité et la maintenabilité de l'application tout en permettant la capitalisation et la réutilisation de composants.
I-B-1. Spring▲
L'utilisation du framework Spring nous permet de garantir le respect strict de la séparation des couches applicatives. En effet, grâce à son moteur d'inversion de contrôle et ses mécanismes d'injections de dépendances, Spring permet aux couches supérieures de ne connaître et de n'utiliser que les interfaces publiques des services qu'elles souhaitent utiliser. C'est le framework lui-même qui se chargera de faire correspondre Interfaces et Implémentations grâce à une configuration xml ou à des annotations Java5 depuis Spring 2.5. En outre, le framework Spring met à disposition un certain nombre d'outils permettant de résoudre les problématiques transverses (sécurité, transactions, etc.) de manière élégante et non intrusive (mécanismes AOP).
I-B-2. Hibernate/JPA▲
Le couple Hibernate/JPA permet de créer, de requêter et de manipuler des objets Java persistants, c'est-à-dire des objets Java correspondant à des enregistrements BDD. Ainsi chaque opération effectuée sur ces objets sera répercutée en base.
Hibernate est l'implémentation concrète du moteur de persistance. Outre le moteur lui-même, il offre un certain nombre d'API de requêtage. JPA offre un niveau d'abstraction supplémentaire en proposant un ensemble d'interfaces standard auxquelles les implémentations d'Hibernate (et d'autres frameworks de persistances) se conforment.
Le moteur de persistance, à travers JPA puis Hibernate, prendra à sa charge la gestion des sessions de connexion à la source de données, les éventuelles libérations de ressources en cas d'erreur, etc.
Une fois les objets persistés, les requêtes se font alors non plus en SQL, mais en JPQL, langage d'interrogation du standard JPA. À noter que ces requêtes portent sur les objets persistés et non les enregistrements en base. On récupère ensuite directement des objets ou des ensemble d'objets directement utilisables.
Insistons quelques instants sur la manipulation de la BDD. Cette manipulation comporte en effet deux aspects :
- la couche DAO publie des méthodes d'accès à la BDD de type création, recherche et suppression d'enregistrements (CREATE, SELECT et DELETE). En bref, cette couche permet de récupérer des instances d'objets à partir d'enregistrement BDD, de créer des nouvelles instances d'objets en créant les enregistrements BDD ou de supprimer des instances existantes en supprimant les enregistrements BDD ;
- le mapping O/R et la persistance des données à travers la couche model permettent, dans un contexte transactionnel, d'effectuer toutes les opérations de type mise à jour (UPDATE). En effet, une fois récupérées, des instances d'objets persistés grâce à la couche DAO, toute modification de l'instance entraînera une modification de l'enregistrement mappé.
Ainsi, la couche DAO ne contiendra, sauf cas particulier d'opérations en masse, aucune méthode de mise à jour d'instances. Ces différents aspects seront détaillés par la suite.
I-B-3. Tapestry 5▲
Tapestry est un framework Java open source orienté composant. Chaque page de l'application web est composée d'une classe Java correspondant à cette même page et du template (H)TML associé.
L'accent est donc mis sur sa simplicité d'utilisation notamment en s'appuyant fortement sur des conventions de nommage évitant ainsi l'écriture de fastidieux fichiers XML de configuration.
La page est alors construite à partir de composants que l'ont peut choisir parmi la liste de composants mis à disposition par Tapestry ou que l'on peut développer soi-même pour des besoins plus spécifiques et réutiliser par la suite.
S'agissant d'une technologie Open Source, il est donc également possible d'intégrer des composants créés par d'autres développeurs. De nombreux composants Ajax ont été développés et peuvent être intégrés dans Tapestry (par exemple : http://87.193.218.134:8080/t5c-demo/).
I-C. Processus de développement▲
Les Makefile ou Ant réalisaient la compilation d'un projet via l'écriture de scripts pour les différentes étapes de la vie du projet. Même avec les directives très abouties de Ant, le script redéfinit pour chaque projet des directives telles que : « compiler les fichiers sources du répertoire src dans le répertoire classes ».
Grâce à Maven, les processus de gestion du projet tout au long de son cycle de vie se retrouvent grandement automatisés, généralisés et simplifiés.
I-C-1. Maven▲
Grâce à Maven, on ne définit plus chacune des opérations à réaliser, mais la structure même du projet à travers un fichier unique (le pom.xml - Project Object Model). À partir de cette définition centralisée, le système Maven déduira seul l'ensemble des tâches qu'il peut effectuer sur le projet et la manière de les mettre en œuvre. L'utilisation de Maven permet de se passer d'écritures de scripts spécifiques.
Maven propose une configuration par défaut très complète qui permet une standardisation de la structure des projets Java. Au besoin, Maven permet de surcharger les configurations pour s'adapter à plus de situations. De cette manière on disposera d'un processus standardisé et extensible favorisant la capitalisation sur différents projets ainsi que l'efficacité quotidienne des équipes de développement.
Grâce à la définition du projet dans le pom.xml, Maven 2 est capable de gérer l'ensemble du cycle de vie d'un projet. Il traite la compilation des fichiers du projet, mais aussi le packaging de l'application (faire une archive War ou Ear n'est pas toujours évident), la gestion des dépendances, la génération des rapports de suivis des développements (checkstyles, tests unitaires…) et même le déploiement de l'application sur un environnement d'exécution.
Généralisé sur une grande majorité des projets Java Open Source (Spring, Hibernate, Struts…), Maven 2 standardise ainsi la gestion d'un projet Java et offre la possibilité d'utiliser des outils qui permettent l'industrialisation du développement via la génération automatique de rapports ou des systèmes d'intégration continue.
Maven, on l'a dit plus haut, permet de standardiser et de structurer un projet. Si cette solution nous apparaît aujourd'hui indispensable pour tout projet Java, il nous semble important de signaler que l'utilisation de Maven impose un certain nombre de contraintes quant à la structure et à l'organisation du projet. Ces contraintes sont les clés mêmes de la standardisation et donc de la force de Maven, elles peuvent cependant dérouter au premier abord. Pour résumer, « maveniser » un projet peut paraître contraignant au premier abord, mais les avantages que cela procure à court, moyen et long terme nous semblent aujourd'hui largement compenser le coût de ce ticket d'entrée.
L'objectif de ce document n'est pas de fournir un tutoriel exhaustif d'utilisation de Maven 2. Il existe de très nombreuses ressources sur le NET expliquant les principes et les avantages de Maven ainsi que son fonctionnement. Pour aller plus loin, vous pouvez commencer par prendre connaissance de la documentation suivante : https://matthieu-lux.developpez.com/tutoriels/java/maven/.
II. Environnement de développement▲
II-A. Installation▲
II-A-1. Eclipse▲
Pour ce tutoriel nous utiliserons l'environnement de développement Eclipse pour Java EE que vous pourrez télécharger ici : http://www.eclipse.org/downloads/.
II-A-2. Plugins▲
Nous utiliserons également les plugins suivants :
- Hibernate Tools : http://www.hibernate.org/subprojects/tools.html;
- M2Eclipse : http://m2eclipse.sonatype.org/.
II-B. Création du projet▲
II-B-1. Dynamic web project▲
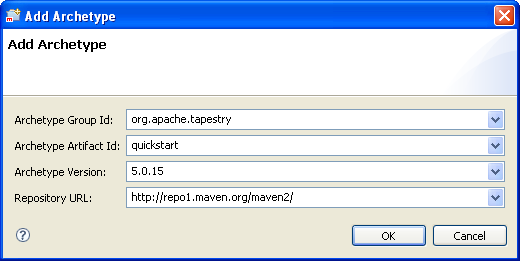
Nous allons maintenant créer notre projet à partir de l'archétype Maven fourni par Tapestry. Pour cela, utilisons l'assistant de création de projets Maven via File -> New -> Maven Project :

Cliquer ensuite sur Next puis Add Archetype… en fournissant les informations suivantes :
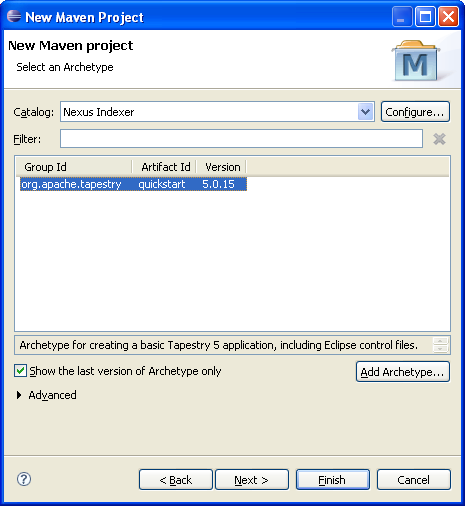
La prochaine étape consistera à renseigner les informations concernant notre projet :
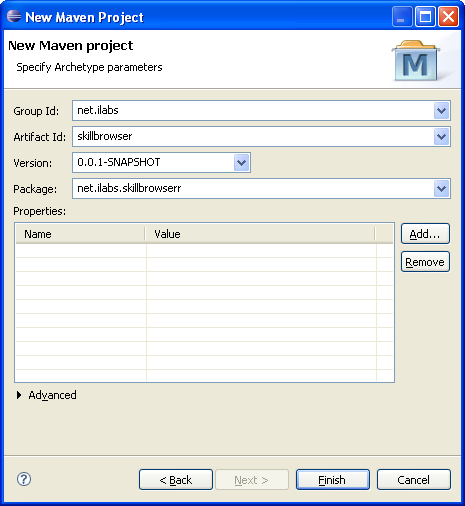
Comme nom de projet, entrons skillbrowser.
II-B-2. Arborescence▲
L'archétype nous a créé les dossiers suivants :
- src/main/ressources dans lequel nous allons placer les fichiers de notre application qui ne sont pas des entités Java. Nous y placerons donc nos fichiers de configuration indépendants de la plateforme et plus particulièrement les fichiers tml : nos pages Tapestry ;
- src/test/java dans lequel nous placerons nos tests unitaires, fonctionnels et tests d'intégration ;
- config dans lequel nous placerons les fichiers de configuration spécifique à la plateforme
Ajoutons ensuite ces trois dossiers au Build Path (clic droit sur le dossier -> Use as Source Folder) de manière à obtenir l'arborescence suivante :
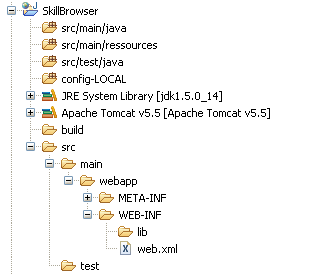
Nous allons maintenant créer les packages qui organiseront notre application (notez bien : les packages parents pour l'instant vides n'apparaissent pas) :

Couche d'accès aux données
- net.ilabs.skillbrowser.domain.model
Pour les classes de notre modèle de données. - net.ilabs.skillbrowser.domain.dao
Pour les interfaces de nos classes d'accès aux données. - net.ilabs.skillbrowser.domain.dao.jpa
Pour les implémentations de notre couche d'accès aux données en utilisant l'API standard Java de persistance de données : JPA.
Couche de service
- net.ilabs.skillbrowser.service
Pour les interfaces de nos classes de service. - net.ilabs.skillbrowser.service.impl
Pour les implémentations de nos classes de service.
Couche de présentation
- net.ilabs.skillbrowser.web.pages
Pour les classes de la couche de présentation Tapestry.
II-B-3. Maven▲
L'archétype Maven a créé le fichier pom.xml (Project Object Model) à la racine de notre application.
II-C. Test de l'environnement avec Tapestry▲
II-C-1. Dépendances▲
Nous allons maintenant tester que notre environnement de développement est bien prêt à fonctionner. Pour cela nous allons d'ores et déjà configurer installer et configurer Tapestry 5 pour notre projet.
Les dépendances Tapestry ont déjà été ajoutées au pom par l'archétype qui nous a permis de créer le projet.
II-C-2. Premier test avec la configuration par défaut▲
Déployons maintenant notre application sur un serveur Tomcat. Pour cela, créez un server Tomcat si ce n'est pas déjà fait puis ajoutez le projet SkillBrowser. Cliquez enfin sur Start the Server depuis votre vue Server de Eclipse :
Pointez alors votre navigateur sur http://localhost:8080/skillbrowser/, vous devriez obtenir le résultat suivant :
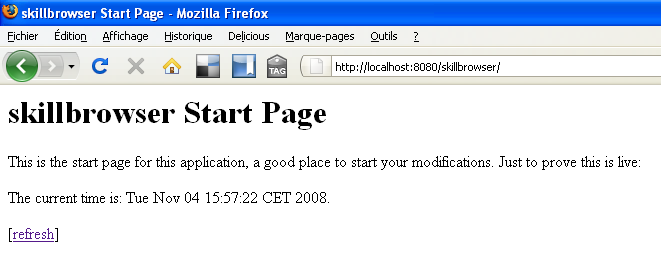
II-C-3. Configuration de Tapestry▲
Il est nécessaire de configurer le filtre Tapestry dans le fichier web.xml. Une configuration par défaut de Tapestry a été effectuée par l'Archetype :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<display-name>SkillBrowser</display-name>
<context-param>
<!-- The only significant configuration for Tapestry 5, this informs Tapestry
of where to look for pages, components and mixins. -->
<param-name>tapestry.app-package</param-name>
<param-value>net.ilabs.skillbrowser.web</param-value>
</context-param>
<filter>
<filter-name>app</filter-name>
<filter-class>org.apache.tapestry5.TapestryFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>app</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>Le paramètre tapestry.app-package permet de designer le package contenant les pages de l'application.
Le filtre Tapestry va intercepter toutes les requêtes entrantes (filter mapping sur /*) pour servir les pages Tapestry. L'archétype utilise le TapestryFilter par défaut, cependant dans le cadre de notre application utilisant Spring, nous devons utiliser org.apache.tapestry5.spring.TapestrySpringFilter.
Nous obtenons donc le web.xml suivant :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<display-name>SkillBrowser</display-name>
<context-param>
<!-- The only significant configuration for Tapestry 5, this informs Tapestry of where to look for pages, components and mixins. -->
<param-name>tapestry.app-package</param-name>
<param-value>net.ilabs.skillbrowser.web</param-value>
</context-param>
<filter>
<filter-name>app</filter-name>
<filter-class>org.apache.tapestry5.spring.TapestrySpringFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>app</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<welcome-file-list>
<welcome-file>Index</welcome-file>
</welcome-file-list>
</web-app>II-C-4. Page d'accueil▲
Nous allons remplacer la page d'Index créée par l'archétype Tapestry. Pour cela, supprimez le package net.ilabs.skillbrowser.pages de src/main/java et src/main/resources puisque nous avons configuré Tapestry pour charger les pages depuis net.ilabs.skillbrowser.web.
Créons donc une page d'accueil en Tapestry 5. Créons tout d'abord la classe Index.java dans le package net.ilabs.skillbrowser.web.pages de src.main.java :
package net.ilabs.skillbrowser.web.pages;
public class Index {
}Puis la page tml correspondante, Index.tml dans le package correspondant du répertoire src/main/resources :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<title>Skill Browser</title>
</head>
<body>
<h1>Skill Browser</h1>
</body>
</html>Il est maintenant temps de déployer notre application sur un serveur Tomcat. Pour cela, créez un server Tomcat si ce n'est pas déjà fait puis ajoutez le projet SkillBrowser. Cliquez enfin sur Start the Server depuis votre vue Server de Eclipse :
Pointez alors votre navigateur sur http://localhost:8080/skillbrowser/, vous devriez obtenir le résultat suivant :

Votre poste est maintenant prêt, nous allons pouvoir commencer le développement de notre application web, comme vous l'aurez compris : le Skill Browser.
III. Skill Browser▲
III-A. Présentation▲
Notre application prétexte à la découverte des technologies abordées par ce tutoriel est un gestionnaire de compétences. Nous l'appellerons le Skill Browser. Il doit permettre :
- de gérer des utilisateurs ;
- de gérer des compétences ;
- d'associer des compétences aux utilisateurs.
III-B. Modèle de données▲
Le modèle est très simple et constitué de deux entités : User et Skill.
User
- String fullname
- String login
- String password
Skill
- String name
IV. Mise en place du modèle de données avec Hibernate/JPA▲
IV-A. Dépendances Hibernate▲
Configurons les dépendances Hibernate dans notre fichier pom.xml.
Configuration des versions :
<properties>
<env>LOCAL</env>
<maven.test.failure.ignore>true</maven.test.failure.ignore>
<mysql-version>5.1.6</mysql-version>
<hibernate-version>3.2.6.GA</hibernate-version>
<hibernate-annotations-version>3.3.1.GA</hibernate-annotations-version>
<hibernate-entitymanager-version>3.3.2.GA</hibernate-entitymanager-version>
<tapestry-version>5.0.18</tapestry-version>
</properties>Ajout des dépendances :
<!-- MySQL -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-version}</version>
</dependency>
<!-- Hibernate -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate</artifactId>
<version>${hibernate-version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-annotations</artifactId>
<version>${hibernate-annotations-version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate-entitymanager-version}</version>
</dependency>IV-B. Création du schéma de base de données▲
Créons les trois tables de notre schéma de BDD :
- la table user pour les utilisateurs ;
- la table skill pour les compétences ;
- la table user_skills pour l'association de compétences aux utilisateurs.
CREATE DATABASE skillbrowser;
CREATE TABLE `skill` (
`skill_id` int(10) unsigned NOT NULL auto_increment,
`name` varchar(45) NOT NULL default '',
PRIMARY KEY (`skill_id`),
UNIQUE KEY `UNIQUE_NAME` USING HASH (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `user` (
`user_id` int(10) unsigned NOT NULL auto_increment,
`login` varchar(25) NOT NULL default '',
`password` varchar(25) NOT NULL default '',
`fullname` varchar(45) NOT NULL default '',
PRIMARY KEY (`user_id`),
UNIQUE KEY `UNIQUE_LOGIN` USING BTREE (`login`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `user_skills` (
`user_id` int(10) unsigned NOT NULL default '0',
`skill_id` int(10) unsigned NOT NULL default '0',
PRIMARY KEY (`user_id`,`skill_id`),
KEY `FK_user_skills_2` (`skill_id`),
CONSTRAINT `FK_user_skills_1` FOREIGN KEY (`user_id`) REFERENCES `user` (`user_id`) ON DELETE CASCADE,
CONSTRAINT `FK_user_skills_2` FOREIGN KEY (`skill_id`) REFERENCES `skill` (`skill_id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=latin1;IV-C. Génération des classes avec annotations JPA▲
Comme décrit précédemment, nous allons utiliser JPA pour la persistance de données. Créons donc le fichier persistence.xml nécessaire à la configuration de JPA dans src/main/resources/META-INF :
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpaTutos" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
</persistence-unit>
</persistence>Créons ensuite le fichier database.properties dans le package net.ilabs.skillbrowser.domain.dao de config pour renseigner la configuration de notre base de données :
hibernate.connection.driver_class=com.mysql.jdbc.Driver
hibernate.connection.url=jdbc:mysql://localhost:3307/skillbrowser
hibernate.connection.username=skillbrowser
hibernate.connection.password=skillbrowser
hibernate.dialect=org.hibernate.dialect.MySQLInnoDBDialect
hibernate.show_sql=true
jpa.dialect=org.springframework.orm.jpa.vendor.HibernateJpaDialect
jpa.vendor.adapter=HibernateJpaVendorAdapterNous allons maintenant générer les classes du modèle de données à partir de notre base de données grâce à Hibernate Tools. Pour cela nous devons d'abord créer une console Hibernate : File -> New -> Other… :
Entrez alors le nom et sélectionnez le projet concerné. Sélectionnez JPA puis parcourez votre projet pour sélectionner le database.properties que nous venons de créer en tant que Property file. La persistence unit est celle que nous avons renseignée dans notre persistence.xml : jpaTutos. Enfin choisissez ImprovedNamingStrategy en naming strategy, cette stratégie de nommage permet d'obtenir une notation 'camelback' du style maNotation plutôt que ma_notation :

Terminez enfin l'assistant en cliquant sur « Finish ».
Une fois la console créée en cliquant sur Finish, il est possible de la modifier. La liste des configurations est affichée dans la vue Hibernate Configurations (pour l'afficher, Window => Show View => Other puis Hibernate Configurations sous la catégorie Hibernate). Déplier la section Database de la configuration permet par ailleurs de vérifier que les paramètres entrés sont corrects.

Ouvrez ensuite le dialogue de génération automatique de code d'Hibernate Tools en cliquant sur :
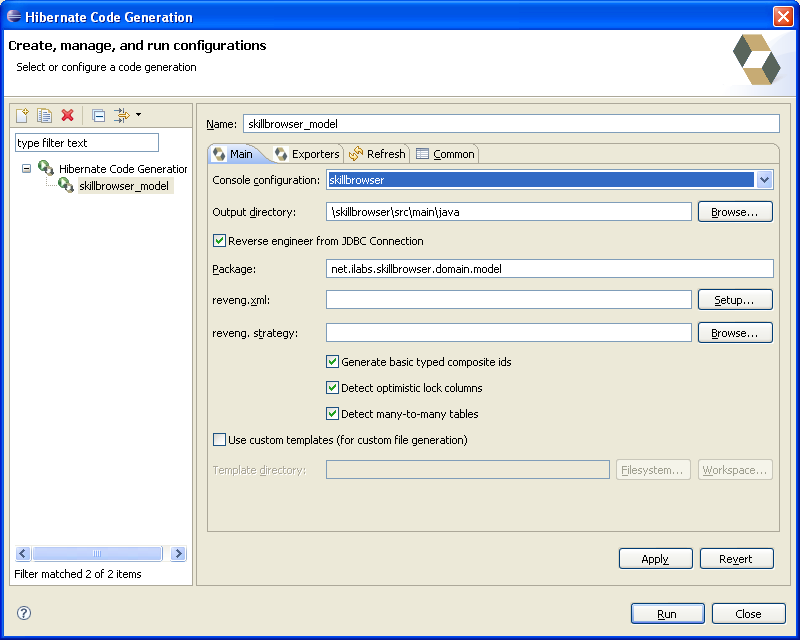
Créer une nouvelle configuration et compléter le premier onglet avec les données suivantes :
Complétez le second onglet « Exporters » en sélectionnant « Domain code (.java) » et en cochant les options :
- Use Java 5 syntax ;
- Generate EJB3 annotations.
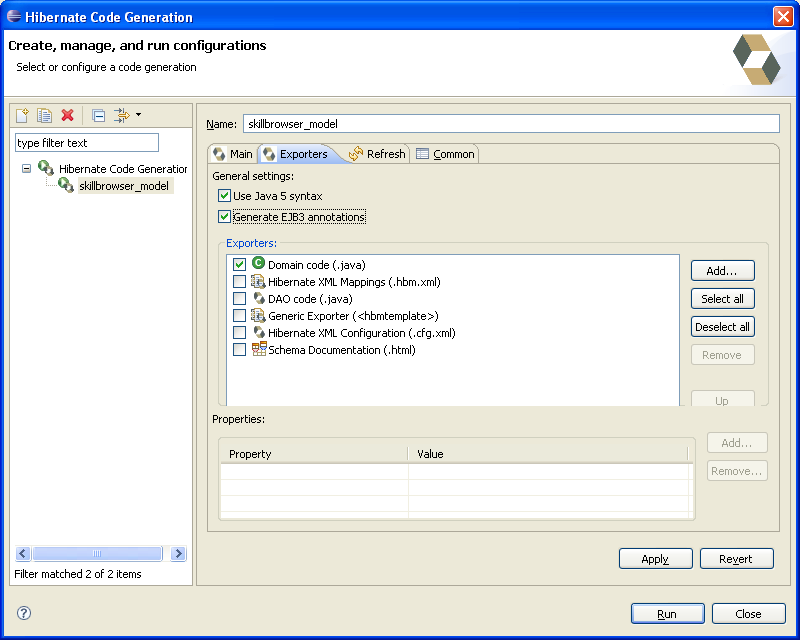
Cliquez alors sur « Run » pour lancer la génération de code. Celle-ci va donc créer à partir de notre schéma de base de données précédemment créé les deux classes suivantes :
package net.ilabs.skillbrowser.domain.model;
// Generated 1 juil. 2008 17:15:44 by Hibernate Tools 3.2.0.CR1
import static javax.persistence.GenerationType.IDENTITY;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.ManyToMany;
import javax.persistence.Table;
import javax.persistence.UniqueConstraint;
/**
* User generated by hbm2java
*/
@Entity
@Table(name = "user", catalog = "tutotapestryspringhibernate", uniqueConstraints = @UniqueConstraint(columnNames = "login"))
public class User implements java.io.Serializable {
private Integer userId;
private String login;
private String password;
private String fullname;
private Set<Skill> skills = new HashSet<Skill>(0);
public User() {
}
public User(String login, String password, String fullname) {
this.login = login;
this.password = password;
this.fullname = fullname;
}
public User(String login, String password, String fullname, Set<Skill> skills) {
this.login = login;
this.password = password;
this.fullname = fullname;
this.skills = skills;
}
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "user_id", unique = true, nullable = false)
public Integer getUserId() {
return this.userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
@Column(name = "login", unique = true, nullable = false, length = 25)
public String getLogin() {
return this.login;
}
public void setLogin(String login) {
this.login = login;
}
@Column(name = "password", nullable = false, length = 25)
public String getPassword() {
return this.password;
}
public void setPassword(String password) {
this.password = password;
}
@Column(name = "fullname", nullable = false, length = 45)
public String getFullname() {
return this.fullname;
}
public void setFullname(String fullname) {
this.fullname = fullname;
}
@ManyToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinTable(name = "user_skills", catalog = "tutotapestryspringhibernate",
joinColumns = { @JoinColumn(name = "user_id", nullable = false, updatable = false) },
inverseJoinColumns = { @JoinColumn(name = "skill_id", nullable = false, updatable = false) })
public Set<Skill> getSkills() {
return this.skills;
}
public void setSkills(Set<Skill> skills) {
this.skills = skills;
}
public void addSkill(Skill skill) {
skills.add(skill);
}
public void removeSkill(Skill skill) {
skills.remove(skill);
}
}Nous rajoutons les méthodes commodes : addSkill et removeSkill en plus des méthodes générées par Hibernate Tools.
package net.ilabs.skillbrowser.domain.model;
// Generated 1 juil. 2008 17:15:44 by Hibernate Tools 3.2.0.CR1
import static javax.persistence.GenerationType.IDENTITY;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.ManyToMany;
import javax.persistence.Table;
import javax.persistence.UniqueConstraint;
/**
* Skill generated by hbm2java
*/
@Entity
@Table(name = "skill", catalog = "tutotapestryspringhibernate", uniqueConstraints = @UniqueConstraint(columnNames = "name"))
public class Skill implements java.io.Serializable {
private Integer skillId;
private String name;
private Set<User> users = new HashSet<User>(0);
public Skill() {
}
public Skill(String name) {
this.name = name;
}
public Skill(String name, Set<User> users) {
this.name = name;
this.users = users;
}
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "skill_id", unique = true, nullable = false)
public Integer getSkillId() {
return this.skillId;
}
public void setSkillId(Integer skillId) {
this.skillId = skillId;
}
@Column(name = "name", unique = true, nullable = false, length = 45)
public String getName() {
return this.name;
}
public void setName(String name) {
this.name = name;
}
@ManyToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY, mappedBy = "skills")
public Set<User> getUsers() {
return this.users;
}
public void setUsers(Set<User> users) {
this.users = users;
}
}Nous noterons les points suivants.
- L'annotation @Entity déclare la classe comme étant un bean entité persistent.
- L'annotation @Id permet de définir l'identifiant et donc la clé primaire de notre entité.
- Les annotations @Column permettent de mapper un membre de la classe sur une colonne de la table correspondante.
- Enfin, l'annotation @ManyToMany permet de définir une association many-to-many. En particulier ici :
Une instance de la classe User possède une collection de compétences : Skill.
Une instance de la classe Skill possède une collection d'utilisateurs : User. - La documentation complète des annotations EJB3 d'Hibernate peut être trouvée à l'adresse suivante : http://docs.jboss.org/ejb3/app-server/HibernateAnnotations/reference/en/html_single/.
V. Couche d'accès aux données▲
La couche d'accès aux données composée de DAO (Data Access Objects) permet la gestion des relations entre les objets du modèle de données et les sources de données, dans notre cas, notre base de données MySQL.
V-A. Dépendances Spring▲
De manière à permettre une utilisation modulaire, Spring Framework a été organisé en modules. Les modules nécessaires à notre application et qui doivent être ajoutés aux dépendances Maven sont les suivants :
Paramétrage de la version de Spring :
<properties>
…………
<spring-version>2.5.6</spring-version>
</properties>Ajout des dépendances :
<!-- Spring Framework -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring-version}</version>
</dependency>
<dependency>
<groupId>org.apache.tapestry</groupId>
<artifactId>tapestry-spring</artifactId>
<version>${tapestry-version}</version>
</dependency>V-B. Configuration▲
Comme vous allez pouvoir le constater, la configuration de JPA avec Spring est très simple. Configurons donc JPA dans le fichier applicationContextJpa.xml que nous créons dans le package net.ilabs.skillbrowser.domain.dao de src/main/resources :
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<!-- Placholders to import inherited variables -->
<bean id="project-properties" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="ignoreUnresolvablePlaceholders">
<value>true</value>
</property>
<property name="locations">
<list>
<value>
classpath*:net/ilabs/skillbrowser/domain/dao/database.properties
</value>
</list>
</property>
</bean>
<!-- post-processors for all standard config annotations -->
<context:annotation-config />
<context:component-scan base-package="net.ilabs.skillbrowser" />
<!-- Exception translation bean post processor -->
<bean class="org.springframework.dao.annotation.PersistenceExceptionTranslationPostProcessor" />
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource" destroy-method="close">
<property name="driverClassName" value="${hibernate.connection.driver_class}" />
<property name="url" value="${hibernate.connection.url}" />
<property name="username" value="${hibernate.connection.username}" />
<property name="password" value="${hibernate.connection.password}" />
</bean>
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="jpaDialect">
<bean class="${jpa.dialect}" />
</property>
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.${jpa.vendor.adapter}">
<property name="showSql" value="${hibernate.show_sql}" />
<property name="databasePlatform" value="${hibernate.dialect}" />
<!-- On ne genere pas la BDD au demarrage -->
<property name="generateDdl" value="false" />
</bean>
</property>
</bean>
<bean id="txManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- enable the configuration of transactional behavior based on annotations -->
<tx:annotation-driven transaction-manager="txManager" />
</beans>- Le premier bean nous permet de référencer le fichier de configuration de note base de données : database.properties.
- Nous configurons ensuite Spring pour utiliser des annotations en lui renseignant le package de base dans lequel il doit automatiquement scanner les classes stéréotypées avec les annotations @Registry et @Service.
- Le bean dataSource permet la configuration de notre source de données grâce aux propriétés de notre database.properties.
- Le bean entityManagerFactory va permettre l'injection de l'EntityManager dans vos DAO. Le paragraphe suivant présente l'EntityManager.
- Nous configurons enfin nos transactions basées sur des annotations en trois lignes.
Enfin configurons Spring dans notre web.xml :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<display-name>SkillBrowser</display-name>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath*:net/ilabs/skillbrowser/domain/dao/applicationContext*.xml</param-value>
</context-param>
<context-param>
<!-- The only significant configuration for Tapestry 5, this informs Tapestry of where to look for pages, components and mixins. -->
<param-name>tapestry.app-package</param-name>
<param-value>net.ilabs.skillbrowser.web</param-value>
</context-param>
<filter>
<filter-name>JpaFilter</filter-name>
<filter-class>org.springframework.orm.jpa.support.OpenEntityManagerInViewFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>JpaFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter>
<filter-name>app</filter-name>
<filter-class>org.apache.tapestry5.spring.TapestrySpringFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>app</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<listener>
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
<welcome-file-list>
<welcome-file>Index</welcome-file>
</welcome-file-list>
</web-app>- Nous ajoutons l'applicationContextJpa.xml dans le context Spring.
- Nous ajoutons l'OpenEntityManagerInViewFilter va nous permettre l'utilisation du lazy-loading et la manipulation de nos entités persistantes dans la couche de présentation.
- Nous enregistrons le Listener Spring : ContextLoaderListener.
V-C. EntityManager▲
Sun a standardisé avec les EJB3 une couche de persistance des données : JPA. L'EntityManager d'Hibernate implémente l'interface de programmation et les cycles de vie définis par la spécification de persistance des données des EJB3. Combiné avec les annotations EJB3 d'Hibernate, nous obtenons une solution complète d'ORM et de persistance des données.
L'EntityManager permet la manipulation des instances d'entités persistantes. Il est alors possible de récupérer (find) et de requêter (query) des entités persistantes ainsi que de les persister (persist), de les mettre à jour (merge) et de les supprimer (remove).
La documentation complète de l'EntityManager se trouve à l'adresse suivante : http://docs.jboss.org/ejb3/app-server/HibernateEntityManager/reference/en/html_single/.
V-D. UserDao▲
Ecrivons maintenant notre DAO de base pour la classe User de notre modèle de données. Voici l'interface à placer dans le package net.ilabs.skillbrowser.domain.dao :
package net.ilabs.skillbrowser.domain.dao;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.User;
/**
* DAO for domain model class User.
*
* @see net.ilabs.skillbrowser.domain.model.User
* @author loic.frering
*/
public interface UserDao {
/**
* Persist a User entity in the database
*
* @param transientUser
*/
public void persist(User transientUser);
/**
* Remove a persisted User from the database
*
* @param persistentUser
*/
public void remove(User persistentUser);
/**
* Remove a persisted User from the database
*
* @param userId
*/
public void remove(Integer userId);
/**
* Update a User in the database
*
* @param detachedUser
* @return merged User
*/
public User merge(User detachedUser);
/**
* Find a User by id
*
* @param id
* @return the found User
*/
public User findById(Integer id);
/**
* Find a User by login
*
* @param login
* @return the found User
*/
public User findByLogin(String login);
/**
* Find a User by fullname
*
* @param fullname
* @return the found User
*/
public User findByFullname(String fullname);
/**
* Find a User by his fullname
*
* @return the found User
*/
public List<User> findAll();
/**
* Search Users
*
* @param searchString
* @return the found Users
*/
public List<User> search(String searchString);
}L'implémentation JPA de notre DAO à placer dans net.ilabs.skillbrowser.domain.dao.jpa :
package net.ilabs.skillbrowser.domain.dao.jpa;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import javax.persistence.Query;
import net.ilabs.skillbrowser.domain.dao.UserDao;
import net.ilabs.skillbrowser.domain.model.User;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.stereotype.Repository;
/**
* DAO for domain model class User.
*
* @see net.ilabs.skillbrowser.domain.model.User
* @author loic.frering
*/
@Repository("userDao")
public class JpaUserDao implements UserDao {
private static final Log log = LogFactory.getLog(JpaUserDao.class);
@PersistenceContext
private EntityManager entityManager;
/**
* {@inheritDoc}
*/
public void persist(User transientUser) {
log.debug("persisting User instance");
try {
entityManager.persist(transientUser);
log.debug("persist successful");
} catch (RuntimeException re) {
log.error("persist failed", re);
}
}
/**
* {@inheritDoc}
*/
public void remove(User persistentUser) {
log.debug("removing User instance");
try {
entityManager.remove(persistentUser);
log.debug("remove successful");
} catch (RuntimeException re) {
log.error("remove failed", re);
}
}
/**
* {@inheritDoc}
*/
public void remove(Integer userId) {
this.remove(this.findById(userId));
}
/**
* {@inheritDoc}
*/
public User merge(User detachedUser) {
log.debug("merging User instance");
try {
User result = entityManager.merge(detachedUser);
log.debug("merge successful");
return result;
} catch (RuntimeException re) {
log.error("merge failed", re);
return null;
}
}
/**
* {@inheritDoc}
*/
public User findById(Integer id) {
log.debug("getting User instance with id: " + id);
try {
User instance = entityManager.find(User.class, id);
log.debug("findById successful");
return instance;
} catch (RuntimeException re) {
log.error("findById failed", re);
return null;
}
}
/**
* {@inheritDoc}
*/
public User findByLogin(String login) {
log.debug("getting User instance with login: " + login);
try {
Query query = entityManager.createQuery("select u from User u where u.login like :login");
query.setParameter("login", login);
User user = (User) query.getSingleResult();
log.debug("findByLogin successful");
return user;
} catch (RuntimeException re) {
log.error("findByLogin failed", re);
return null;
}
}
/**
* {@inheritDoc}
*/
public User findByFullname(String fullname) {
log.debug("getting User instance with fullname: " + fullname);
try {
Query query = entityManager.createQuery("select u from User u where u.fullname like :fullname");
query.setParameter("fullname", fullname);
User user = (User) query.getSingleResult();
log.debug("findByFullname successful");
return user;
} catch (RuntimeException re) {
log.error("findByFullname failed", re);
return null;
}
}
/**
* {@inheritDoc}
*/
public List<User> findAll() {
log.debug("getting all User instances");
try {
Query query = entityManager.createQuery("select u from User u");
List<User> userList = (List<User>) query.getResultList();
log.debug("findAll successful");
return userList;
} catch (RuntimeException re) {
log.error("findAll failed", re);
return new ArrayList<User>();
}
}
/**
* {@inheritDoc}
*/
public List<User> search(String searchString) {
log.debug("Search User instances with search string: " + searchString);
try {
Query query = entityManager.createQuery("select u from User u where u.login like :searchString or u.fullname like :searchString");
query.setParameter("searchString", searchString);
List<User> userList = (List<User>) query.getResultList();
log.debug("search successful");
return userList;
} catch (RuntimeException re) {
log.error("search failed", re);
return new ArrayList<User>();
}
}
}V-E. SkillDao▲
L'interface de notre SkillDao reprend les mêmes méthodes que celles présentées pour le UserDao. À placer dans net.ilabs.skillbrowser.domain.dao :
package net.ilabs.skillbrowser.domain.dao;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.Skill;
/**
* DAO for domain model class Skill.
*
* @see net.ilabs.skillbrowser.domain.model.Skill
* @author loic.frering
*/
public interface SkillDao {
/**
* Persist a Skill entity in the database
*
* @param transientSkill
*/
public void persist(Skill transientSkill);
/**
* Remove a persisted Skill from the database
*
* @param persistentSkill
*/
public void remove(Skill persistentSkill);
/**
* Remove a persisted Skill from the database
*
* @param persistentSkill
*/
public void remove(Integer skillId);
/**
* Update a Skill in the database
*
* @param detachedSkill
* @return merged Skill
*/
public Skill merge(Skill detachedSkill);
/**
* Find a Skill by id
*
* @param id
* @return the found Skill
*/
public Skill findById(Integer id);
/**
* Find a Skill by name
*
* @param id
* @return the found Skill
*/
public Skill findByName(String name);
/**
* Find all Skills
*
* @param id
* @return the found Skills
*/
public List<Skill> findAll();
}L'implémentation JPA de notre SkillDao à placer dans net.ilabs.skillbrowser.domain.dao.jpa :
package net.ilabs.skillbrowser.domain.dao.jpa;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import javax.persistence.Query;
import net.ilabs.skillbrowser.domain.dao.SkillDao;
import net.ilabs.skillbrowser.domain.model.Skill;
import net.ilabs.skillbrowser.domain.model.User;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.stereotype.Repository;
/**
* JPA implementation of the DAO for domain model class Skill.
*
* @see net.ilabs.skillbrowser.domain.model.Skill
* @author loic.frering
*/
@Repository("skillDao")
public class JpaSkillDao implements SkillDao {
private static final Log log = LogFactory.getLog(JpaSkillDao.class);
@PersistenceContext
private EntityManager entityManager;
/**
* {@inheritDoc}
*/
public void persist(Skill transientSkill) {
log.debug("persisting Skill instance");
try {
entityManager.persist(transientSkill);
log.debug("persist successful");
} catch (RuntimeException re) {
log.error("persist failed", re);
}
}
/**
* {@inheritDoc}
*/
public void remove(Skill persistentSkill) {
log.debug("removing Skill instance");
try {
entityManager.remove(persistentSkill);
log.debug("remove successful");
} catch (RuntimeException re) {
log.error("remove failed", re);
}
}
/**
* {@inheritDoc}
*/
public void remove(Integer skillId) {
this.remove(this.findById(skillId));
}
/**
* {@inheritDoc}
*/
public Skill merge(Skill detachedSkill) {
log.debug("merging Skill instance");
try {
Skill result = entityManager.merge(detachedSkill);
log.debug("merge successful");
return result;
} catch (RuntimeException re) {
log.error("merge failed", re);
return null;
}
}
/**
* {@inheritDoc}
*/
public Skill findById(Integer id) {
log.debug("getting Skill instance with id: " + id);
try {
Skill instance = entityManager.find(Skill.class, id);
log.debug("findById successful");
return instance;
} catch (RuntimeException re) {
log.error("findById failed", re);
return null;
}
}
/**
* {@inheritDoc}
*/
public Skill findByName(String name) {
log.debug("getting Skill instance with name: " + name);
try {
Query query = entityManager.createQuery("select s from Skill s where s.name like :name");
query.setParameter("name", name);
Skill skill = (Skill) query.getSingleResult();
log.debug("findByName successful");
return skill;
} catch (RuntimeException re) {
log.error("findByName failed", re);
return null;
}
}
/**
* {@inheritDoc}
*/
public List<Skill> findAll() {
log.debug("getting all Skill instances");
try {
Query query = entityManager.createQuery("select s from Skill s order by s.name asc");
List<Skill> skillList = query.getResultList();
log.debug("findAll successful");
return skillList;
} catch (RuntimeException re) {
log.error("findAll failed", re);
return new ArrayList<Skill>();
}
}
}VI. Couche de services▲
Dans le cadre de notre tutoriel, notre couche de service va essentiellement permettre d'exposer les méthodes de notre DAO. Pour une application complète, la couche de service doit implémenter tout le métier de notre application comme nous l'avons vu en première partie.
VI-A. UserManager▲
L'interface de notre UserManager expose les méthodes du UserDao en plus du métier concernant nos utilisateurs :
package net.ilabs.skillbrowser.service;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.User;
/**
* Manager for domain model class User
*
* @see net.ilabs.skillbrowser.service.User
* @author loic.frering
*/
public interface UserManager {
/**
* Persist a User entity in the database
*
* @param transientUser
*/
public void persist(User transientUser);
/**
* Remove a persisted User from the database
*
* @param persistentUser
*/
public void remove(User persistentUser);
/**
* Update a User in the database
*
* @param detachedUser
* @return merged User
*/
public User merge(User detachedUser);
/**
* Find a User by id
*
* @param id
* @return the found User
*/
public User findById(Integer id);
/**
* Find a User by login
*
* @param login
* @return the found User
*/
public User findByLogin(String login);
/**
* Find a User by fullname
*
* @param fullname
* @return the found User
*/
public User findByFullname(String fullname);
/**
* Find a User by his fullname
*
* @return the found User
*/
public List<User> findAll();
/**
* Search Users
*
* @param searchString
* @return the found Users
*/
public List<User> search(String searchString);
}
L'implémentation :
package net.ilabs.skillbrowser.service.impl;
import java.util.List;
import net.ilabs.skillbrowser.domain.dao.UserDao;
import net.ilabs.skillbrowser.domain.model.User;
import net.ilabs.skillbrowser.service.UserManager;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
@Service("userManager")
@Transactional(propagation = Propagation.REQUIRED, readOnly = true)
public class UserManagerImpl implements UserManager {
private final Log log = LogFactory.getLog(this.getClass());
@Autowired
private UserDao userDao;
/**
* {@inheritDoc}
*/
public List<User> findAll() {
return userDao.findAll();
}
/**
* {@inheritDoc}
*/
public User findByFullname(String fullname) {
return userDao.findByFullname(fullname);
}
/**
* {@inheritDoc}
*/
public User findById(Integer id) {
return userDao.findById(id);
}
/**
* {@inheritDoc}
*/
public User findByLogin(String login) {
return userDao.findByLogin(login);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public User merge(User detachedUser) {
return userDao.merge(detachedUser);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public void persist(User transientUser) {
userDao.persist(transientUser);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public void remove(User persistentUser) {
userDao.remove(persistentUser);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public void remove(Integer userId) {
userDao.remove(userId);
}
/**
* {@inheritDoc}
*/
public List<User> search(String searchString) {
return userDao.search(searchString);
}
}VI-B. SkillManager▲
De la même manière, voici l'interface SkillManager :
package net.ilabs.skillbrowser.service;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.Skill;
/**
* Manager for domain model class Skill.
*
* @see net.ilabs.skillbrowser.domain.model.Skill
* @author loic.frering
*/
public interface SkillManager {
/**
* Persist a Skill entity in the database
*
* @param transientSkill
*/
public void persist(Skill transientSkill);
/**
* Remove a persisted Skill from the database
*
* @param persistentSkill
*/
public void remove(Skill persistentSkill);
/**
* Update a Skill in the database
*
* @param detachedSkill
* @return merged Skill
*/
public Skill merge(Skill detachedSkill);
/**
* Find a Skill by id
*
* @param id
* @return the found Skill
*/
public Skill findById(Integer id);
/**
* Find a Skill by name
*
* @param id
* @return the found Skill
*/
public Skill findByName(String name);
/**
* Find all Skills
*
* @param id
* @return the found Skills
*/
public List<Skill> findAll();
}Et l'implémentation :
package net.ilabs.skillbrowser.service.impl;
import java.util.List;
import net.ilabs.skillbrowser.domain.dao.SkillDao;
import net.ilabs.skillbrowser.domain.model.Skill;
import net.ilabs.skillbrowser.service.SkillManager;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
@Service("skillManager")
@Transactional(propagation = Propagation.REQUIRED, readOnly = true)
public class SkillManagerImpl implements SkillManager {
private final Log log = LogFactory.getLog(this.getClass());
@Autowired
private SkillDao skillDao;
/**
* {@inheritDoc}
*/
public List<Skill> findAll() {
return skillDao.findAll();
}
/**
* {@inheritDoc}
*/
public Skill findById(Integer id) {
return skillDao.findById(id);
}
/**
* {@inheritDoc}
*/
public Skill findByName(String name) {
return skillDao.findByName(name);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public Skill merge(Skill detachedSkill) {
return skillDao.merge(detachedSkill);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public void persist(Skill transientSkill) {
skillDao.persist(transientSkill);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public void remove(Skill persistentSkill) {
skillDao.remove(persistentSkill);
}
/**
* {@inheritDoc}
*/
@Transactional(readOnly = false)
public void remove(Integer skillId) {
skillDao.remove(skillId);
}
}VI-C. Configuration par annotations▲
Nos classes de la couche service sont annotées @Service. Cette annotation dérivée de l'annotation @Component Spring définit un composant de la couche service géré par Spring et déclare donc un bean sans que l'on ait besoin de passer par la lourde configuration déclarative par fichiers XML de Spring 2.0.
Une autre nouveauté de Spring 2.5 est l'auto détection de composants. Ainsi l'annotation @Autowired sur les membres de nos classes de services va permettre l'injection automatique des beans correspondants. La correspondance se fait par type par défaut, mais ce comportement peut être facilement paramétré pour obtenir un cablage automatique par nom par exemple.
VI-D. Transactions▲
Comme nous l'avons vu dans le paragraphe précédent, nous avons configuré les transactions pour qu'elles fonctionnent par annotations. Ainsi, comme nous avons pu le voir dans les classes précédentes, il est très facile de configurer nos classes pour qu'elles soient invoquées dans un contexte transactionnel en read only par défaut grâce à l'annotation :
@Transactional(propagation = Propagation.REQUIRED, readOnly = true)On peut alors de la même manière configurer indépendamment chacune de nos méthodes pour qu'elles soient invoquées en lecture et écriture grâce à l'annotation suivante :
@Transactional(readOnly = false)VII. Couche de présentation▲
VII-A. Dépendances Tapestry5▲
Les dépendances Tapestry5 ont été ajoutées par l'archétype Maven utilisé précédemment lors de la création du projet.
VII-B. Gestion des utilisateurs▲
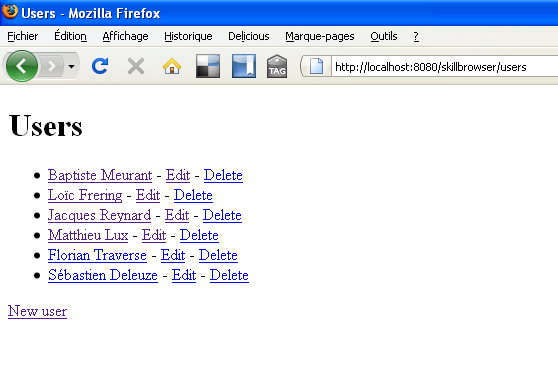
VII-B-1. Lister les utilisateurs▲
Comme nous l'avons vu dans la partie 2.3.2, nous avons configuré Tapestry pour que ses pages se trouvent dans le package net.ilabs.skillbrowser.web.pages. Nous allons créer à cet endroit un package users qui contiendra les pages de notre gestion d'utilisateurs. Créons tout d'abord la classe UsersIndex dans net.ilabs.skillbrowser.web.pages.users de src/main/java :
package net.ilabs.skillbrowser.web.pages.users;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.User;
import net.ilabs.skillbrowser.service.UserManager;
import org.apache.tapestry5.annotations.Service;
import org.apache.tapestry5.ioc.annotations.Inject;
public class UsersIndex {
@Inject
private UserManager userManager;
@Property
private User user;
public List<User> getUserList() {
return userManager.findAll();
}
public void onActionFromDeleteUser(Integer userId) {
userManager.remove(userId);
}
}- L'annotation @Inject nous permet d'injecter notre userManager Spring. Cette injection ne provoquant aucune ambiguïté, il n'est pas nécessaire de préciser le nom du service Spring à injecter. Nous verrons l'utilisation de l'annotation @Service complémentaire au paragraphe 7.4.
- La méthode getUserList va nous permettre de récupérer la liste complète de nos utilisateurs.
- L'attribut user permettra le parcours de la liste précédente. Ainsi chaque élément de cette liste pourra être accédé par la vue via cette propriété. Elle est également précédée de l'annotation @Property qui va automatiquement créer les getter et setter pour cet attribut. Ainsi nous nous économisons l'écriture des méthodes getUser et setUser.
- Le composant actionlink que nous verrons dans la page tml déclenche l'évèvenement « action ». Par convention de nommage la méthode onActionFromDeleteUser va intercepter les évènements « action » qui auront été déclenchés par un composant d'id deleteUser. Cette méthode nous permettra donc de supprimer un utilisateur lors du clic sur l'actionlink deleteUser.
Voilà maintenant le template correspondant :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<title>Users</title>
</head>
<body>
<h1>Users</h1>
<ul>
<li t:type="loop" t:source="userList" t:value="user">
${user.fullname}
- <t:pagelink page="users/Save" context="user.userId">Edit</t:pagelink>
- <t:actionlink t:id="deleteUser" context="user.userId">Delete</t:actionlink>
</li>
</ul>
<p>
<t:pagelink page="users/Save">New user</t:pagelink>
</p>
</body>
</html>Tout élément HTML est susceptible de contenir un attribut Tapestry t:type=« loop » qui produira sa répétition sur tous les éléments de la liste passée à l'attribut t:source et dont l'élément courant est identifié par la valeur de l'attribut t:value. Pour que la liste puisse être parcourue et comme nous l'avons vu lors de l'implémentation de la page, des méthodes getter et setter doivent être mises à disposition pour l'élément courant du parcourt de la liste, soit setUser et getUser.
Le composant pagelink permettra la redirection vers la page d'édition de l'utilisateur avec son identifiant en contexte.
Le composant actionlink deleteUser permettra la suppression de l'utilisateur dont l'identifiant est aussi passé en contexte.
VII-B-2. Ajouter un utilisateur▲
L'ajout et l'édition d'un utilisateur se feront par l'intermédiaire de la même page : UsersSave. La présence d'un identifiant en contexte permettra de passer en édition d'un utilisateur plutôt qu'en création d'un nouvel utilisateur.
Créons donc la classe UsersSave dans net.ilabs.skillbrowser.web.pages.users de src/main/java :
package net.ilabs.skillbrowser.web.pages.users;
import net.ilabs.skillbrowser.domain.model.User;
import net.ilabs.skillbrowser.service.UserManager;
import org.apache.tapestry5.annotations.Component;
import org.apache.tapestry5.corelib.components.Form;
import org.apache.tapestry5.corelib.components.TextField;
import org.apache.tapestry5.ioc.annotations.Inject;
import org.springframework.dao.DataIntegrityViolationException;
public class UsersSave {
@Inject
private UserManager userManager;
@Component(id = "add_user_form")
private Form addUserForm;
@Component
private TextField userLogin;
@Property
private User user;
public void onActivate() {
user = new User();
}
public Boolean onActivate(Integer id) {
user = userManager.findById(id);
if(null == user) {
return false;
}
return true;
}
public Integer onPassivate() {
return (user != null) ? user.getUserId() : null;
}
public String onSuccess() {
try {
userManager.persist(user);
} catch (DataIntegrityViolationException dive) {
addUserForm.recordError(userLogin, dive.getMostSpecificCause().getMessage());
return null;
}
return "users/UsersIndex";
}
// Necessary cause ValidationTrackers are stored into session and so record
// errors would not be cleaned automatically
void cleanupRender() {
addUserForm.clearErrors();
}
}De même que précédemment, nous retrouvons ici l'injection du UserManager
Les attributs addUserForm de type Form et userLogin de type TextField sont précédés de l'annotation @Component. Cette annotation définit des éléments du template embarqué dans notre classe. Ainsi, comme nous le verrons plus loin, add_user_form est l'identifiant de notre élément formulaire et userLogin est l'identifiant d'un champ de formulaire destiné à recevoir le login de l'utilisateur.
Lorsqu'une page est invoquée, celle-ci est activée avant d'être rendue, cela va permettre d'initialiser le contexte de la page. Le contexte permet de définir l'état de la page lors de son rendu. Concrètement le contexte d'une page est souvent l'identifiant d'un objet persistant du modèle de donnée. Ces paramètres de contexte sont ajoutés à l'URL d'invocation de la page. Par exemple le lien d'édition d'un utilisateur sera : http://localhost:8080/skillbrowser/users/save/24 où 24 est l'identifiant de l'utilisateur à modifier.
On peut passer au context de la page autant de paramètres que l'on souhaite. Ainsi, en fonction du nombre de paramètres passés, la méthode onActivate contenant le nombre adéquat de paramètres sera appelée. Ainsi, si on passe deux paramètres de type chaîne de caractères, la méthode onActivate(String arg0, String arg1) sera appelée avant une éventuelle méthode onActivate(String arg0).
Il est important de noter que les méthodes onActivate avec moins de paramètres seront appelées en cascade même si la méthode qui correspond avec le plus grand nombre de paramètres a été précédemment exécutée. Pour éviter ce comportement, il est nécessaire de dire à Tapestry que vous ne souhaitez pas appeler les méthodes d'activation suivantes en renvoyant true en retour de méthode. À l'inverse, retourner false ou void provoquera l'appel en cascade des méthodes d'activation.
Une fois l'identifiant de l'utilisateur récupéré, nous pouvons alors récupérer l'entité correspondante via le UserManager.
Si la page est appelée sans contexte, dans le cas de la création d'un utilisateur, nous passons dans la méthode onActivate() sans paramètre et nous instancions alors un nouvel utilisateur.
La méthode onSuccess() sera invoquée une fois le formulaire validé et les validateurs passés (nous détaillerons les validateurs un peu plus loin). L'utilisateur est alors renvoyé sur la page désignée par la chaîne de caractère renvoyée par la méthode.
Si une exception est interceptée dans cette méthode, nous enregistrons une erreur sur notre composant formulaire décrit précédemment grâce à la méthode recordError. Nous spécifions sur quel champ doit porter l'erreur en lui passant le composant userLogin en second paramètre.
Il est aussi possible de lever des erreurs dans la méthode onSuccess. Dans notre cas, si DataIntegrityViolationException est catchée (dans le cas d'un user déjà existant) une erreur est enregistrée sur l'objet addUserForm et null est retourné. L'utilisateur est donc retourné sur la même page de formulaire avec l'erreur correspondante affichée pour qu'il modifie les données saisies.
Examinons maintenant le template correspondant pour la sauvegarde d'un utilisateur : UsersSave.tml dans net.ilabs.skillbrowser.web.pages.users de src/main/resources :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<title>Add a user</title>
</head>
<body>
<h1>Add a user</h1>
<t:form t:id="add_user_form">
<fieldset>
<legend>New user</legend>
<t:errors />
<p>
<t:label for="userFullname">Fullname</t:label>
<t:textfield t:id="userFullname" t:value="user.fullname" t:validate="required" />
</p>
<p>
<t:label for="userLogin">Login</t:label>
<t:textfield t:id="userLogin" t:value="user.login" t:validate="required" />
</p>
<p>
<t:label for="userPassword">Password</t:label>
<t:textfield t:id="userPassword" t:value="user.password" t:validate="required" />
</p>
<p>
<t:submit t:id="submit" value="Submit" />
</p>
</fieldset>
</t:form>
<p>
<t:pagelink page="users/Index">Cancel</t:pagelink>
</p>
</body>
</html>Notons
Les balises Tapestry de formulaire : t:textfield, t:submit… et leurs attributs associés. Pour la liste des composants Tapestry, référez-vous au site. Soulignons particulièrement t:validate qui va vous permettre d'ajouter très facilement des validateurs à vos formulaires pour rendre vos champs obligatoires, pour qu'ils correspondent à une expression régulière configurée, pour qu'ils aient une longueur minimale… Pour plus d'informations sur les validateurs Tapestry : http://tapestry.apache.org/user-guide.html.
La balise t:errors permet l'affichage des erreurs de validation du formulaire et des erreurs enregistrées grâce à la méthode recordError vue précédemment.
VII-C. Gestion des compétences▲
La gestion des compétences est identique à la gestion des utilisateurs. Nous ne détaillerons donc pas de nouveau le code. Cependant comme expliqué précédemment, nous avons utilisé les conventions de nommage pour câbler les évènements des composants Tapestry sur les méthodes de la classe Java correspondante. Pour la gestion des compétences, nous allons utiliser une autre façon de faire : l'utilisation des annotations. L'utilisation de l'une ou l'autre de ces méthodes est une simple question de préférence.
Créons donc la classe SkillsIndex qui va nous permettre de lister les compétences dans net.ilabs.skillbrowser.web.pages.skills de src/main/java :
package net.ilabs.skillbrowser.web.pages.skills;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.Skill;
import net.ilabs.skillbrowser.service.SkillManager;
import org.apache.tapestry5.annotations.OnEvent;
import org.apache.tapestry5.annotations.Property;
import org.apache.tapestry5.ioc.annotations.Inject;
public class SkillsIndex {
@Inject
private SkillManager skillManager;
@Property
private Skill skill;
public List<Skill> getSkillList() {
return skillManager.findAll();
}
@OnEvent(value="action", component="DeleteSkill")
public void deleteSkill(Integer skillId) {
skillManager.remove(skillId);
}
}Notons ici l'annotation @OnEvent sur la méthode deleteSkill. Ainsi celle-ci remplace la précédente méthode onActionFromDeleteSkill et sera donc invoquée sur le déclenchement d'un évènement action depuis le composant d'identifiant deleteSkill.
La page tml correspondante est SkillsSave.tml dans le package net.ilabs.skillbrowser.web.pages.skills de src/main/resources :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<title>Skills</title>
</head>
<body>
<h1>Skills</h1>
<ul>
<li t:type="loop" t:source="skillList" t:value="skill">
${skill.name}
- <t:pagelink page="skills/Save" context="skill.skillId">Edit</t:pagelink>
- <t:actionlink t:id="deleteSkill" context="skill.skillId">Delete</t:actionlink>
</li>
</ul>
<p>
<t:pagelink page="skills/Save">New skill</t:pagelink>
</p>
</body>
</html>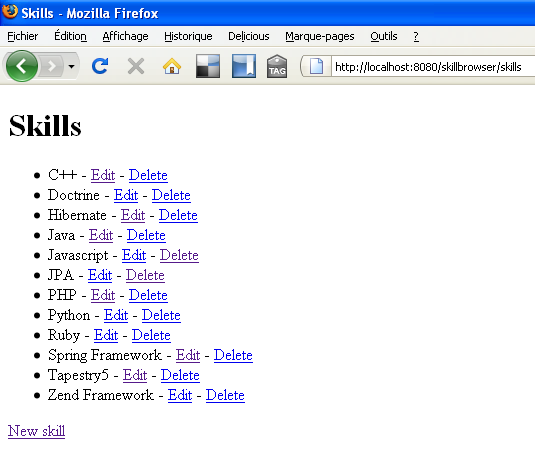
Créons maintenant la classe SkillsSave qui va nous permettre de sauvegarder et éditer des compétences dans net.ilabs.skillbrowser.web.pages.skills de src/main/java :
package net.ilabs.skillbrowser.web.pages.skills;
import net.ilabs.skillbrowser.domain.model.Skill;
import net.ilabs.skillbrowser.service.SkillManager;
import org.apache.tapestry5.annotations.Component;
import org.apache.tapestry5.annotations.OnEvent;
import org.apache.tapestry5.annotations.Property;
import org.apache.tapestry5.corelib.components.Form;
import org.apache.tapestry5.corelib.components.TextField;
import org.apache.tapestry5.ioc.annotations.Inject;
import org.springframework.dao.DataIntegrityViolationException;
public class SkillsSave {
@Inject
private SkillManager skillManager;
@Component(id = "add_skill_form")
private Form addSkillForm;
@Component
private TextField skillName;
@Property
private Skill skill;
@OnEvent("activate")
public void activate() {
skill = new Skill();
}
@OnEvent("activate")
public Boolean activate(Integer id) {
skill = skillManager.findById(id);
if(null == skill) {
return false;
}
return true;
}
@OnEvent("passivate")
public Integer passivate() {
return (skill != null) ? skill.getSkillId() : null;
}
@OnEvent(Form.SUCCESS)
public String addSkillSuccess() {
try {
skillManager.persist(skill);
} catch (DataIntegrityViolationException dive) {
addSkillForm.recordError(skillName, dive.getMostSpecificCause().getMessage());
return null;
} catch (Exception e) {
addSkillForm.recordError(skillName, e.getMessage());
return null;
}
return "skills/SkillsIndex";
}
// Necessary cause ValidationTrackers are stored into session and so record
// errors would not be cleaned automatically
void cleanupRender() {
addSkillForm.clearErrors();
}
}De même que précédemment, nous utilisons ici l'annotation @OnEvent(« activate ») sur les méthodes d'activation plutôt que d'utiliser nommage par convention : onActivate(). Ainsi les méthodes annotées comme cela seront invoquées à l'activation de la page par Tapestry.
L'annotation @OnEvent prend en paramètre par défaut l'évènement si celui-ci n'est pas spécifié explicitement, par exemple : @OnEvent(« activate ») correspond à @OnEvent(value=« activate »).
De la même manière, les annotations @OnEvent(« passivate ») et @OnEvent(Form.SUCCESS) permettent d'invoquer les méthodes correspondantes sur les évènements success (soumission du formulaire) et passivate.
Le template correspondant : SkillsSave.tml dans net.ilabs.skillbrowser.web.pages.skills de src/main/resources :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<title>Add a skill</title>
</head>
<body>
<h1>Add a skill</h1>
<t:form t:id="add_skill_form" accept-charset="iso-8859-1">
<fieldset>
<legend>New skill</legend>
<t:errors />
<p>
<t:label for="skillName">Name</t:label>
<t:textfield t:id="skillName" t:value="skill.name" t:validate="required" />
</p>
<p>
<t:submit t:id="submit" value="Submit" />
</p>
</fieldset>
</t:form>
<p>
<t:pagelink page="skills/Index">Cancel</t:pagelink>
</p>
</body>
</html>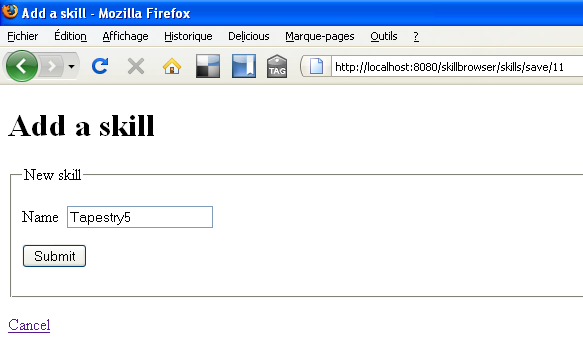
VII-D. Compétences d'un utilisateur▲
Nous allons maintenant créer la page qui permettra d'affecter des compétences à un utilisateur. Pour cela, créons la classe UsersSkills dans le package net.ilabs.skillbrowser.web.pages.users de src/main/java :
package net.ilabs.skillbrowser.web.pages.users;
import java.util.ArrayList;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.Skill;
import net.ilabs.skillbrowser.domain.model.User;
import net.ilabs.skillbrowser.service.SkillManager;
import net.ilabs.skillbrowser.service.UserManager;
import org.apache.tapestry5.annotations.Service;
import org.apache.tapestry5.ioc.annotations.Inject;
public class UsersSkills {
@Inject
@Service("userManager")
private UserManager userManager;
@Inject
@Service("skillManager")
private SkillManager skillManager;
@Property
private User user;
@Property
private Skill skill;
public List<Skill> getSkills() {
return skillManager.findAll();
}
public List<Skill> getUserSkills() {
return new ArrayList<Skill>(user.getSkills());
}
public void onActivate(Integer id) {
user = userManager.findById(id);
}
public Integer onPassivate() {
return user.getUserId();
}
public String onActionFromAddSkill(Integer skillId) {
user.addSkill(skillManager.findById(skillId));
userManager.persist(user);
return null;
}
public String onActionFromDeleteSkill(Integer skillId) {
return onActionFromDeleteUserSkill(skillId);
}
public String onActionFromDeleteUserSkill(Integer skillId) {
user.removeSkill(skillManager.findById(skillId));
userManager.persist(user);
return null;
}
}Nous injectons les services Spring UserManager et SkillManager qui nous permettront de récupérer les compétences et de les affecter à des utilisateurs. Pour cette classe, et pour information, nous utilisons en plus de l'annotation @Inject, l'annotation @Service (attention à bien importer l'annotation Service de Tapestry) qui nous permet de préciser que nous souhaitons injecter un service et non un composant Tapestry et qui nous permet aussi de préciser le nom du service à injecter.
- La variable user contiendra l'utilisateur courant auquel nous allons affecter des compétences.
- La variable skill permettra le parcours de la liste de toutes les compétences pour leur affichage.
- La méthode getSkills retourne la liste de toutes les compétences grâce à un appel au skill manager.
- La méthode getUserSkills retourne les compétences de l'utilisateur courant.
- La méthode onActionFromAddSkill sera invoquée (par convention de nommage) lors du clic sur l'actionlink d'identifiant addSkill. L'identifiant de la compétence à ajouter est passé en context de l'actionlink et se retrouvera donc en paramètre de la méthode. La méthode s'occupe alors d'ajouter la compétence à l'utilisateur et à la persister grâce au UserManager.
- Enfin la méthode onActionFromDeleteUserSkill va de la même manière récupérer l'identifiant da la compétence à supprimer, la supprimer effectivement et persister l'utilisateur.
La vue correspondante :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<title>Skills for ${user.fullname}</title>
</head>
<body>
<h1>Skills for ${user.fullname}</h1>
<fieldset xmlns="http://www.w3.org/1999/xhtml">
<t:loop source="skills" value="skill">
<t:actionlink t:id="addSkill" context="skill.skillId">${skill.name}</t:actionlink>
</t:loop>
</fieldset>
<ul xmlns="http://www.w3.org/1999/xhtml">
<li t:type="loop" t:source="userSkills" t:value="skill">
${skill.name}
- <t:actionlink t:id="deleteUserSkill" context="skill.skillId">Delete</t:actionlink>
</li>
</ul>
<p>
<t:pagelink page="users/Index">Back</t:pagelink>
</p>
</body>
</html>Dans le fieldset seront listées toutes les compétences avec un actionlink sur chacune d'entre elles permettant leur ajout à l'utilisateur.
Le ul suivant va lister toutes les compétences actuellement affectées à l'utilisateur et va permettre leur suppression via un actionlink.
VII-D-1. Une touche d'Ajax▲
Précédemment, le clic sur un actionlink provoquait le traitement de l'action et le rechargement de la page de compétences de l'utilisateur actualisée puisque la méthode retourne null. Nous allons donc nous efforcer d'ajouter un peu d'Ajax à notre page, particulièrement, nous aborderons les points suivants :
- la requête de la liste de compétences en Ajax évitant que celle-ci soit chargée si l'on souhaite simplement consulter les compétences ;
- l'ajout d'une compétence en Ajax sans rechargement de la page ;
- la suppression d'une compétence en Ajax.
Pour ce faire, voici le nouveau code Java de la page :
package net.ilabs.skillbrowser.web.pages.users;
import java.util.ArrayList;
import java.util.List;
import net.ilabs.skillbrowser.domain.model.Skill;
import net.ilabs.skillbrowser.domain.model.User;
import net.ilabs.skillbrowser.service.SkillManager;
import net.ilabs.skillbrowser.service.UserManager;
import org.apache.tapestry5.Block;
import org.apache.tapestry5.annotations.Component;
import org.apache.tapestry5.annotations.Service;
import org.apache.tapestry5.corelib.components.Zone;
import org.apache.tapestry5.ioc.annotations.Inject;
public class UsersSkills {
@Inject
@Service("userManager")
private UserManager userManager;
@Inject
@Service("skillManager")
private SkillManager skillManager;
@Inject
private Block addSkillsBlock;
@Component
private Zone userSkillsZone;
@Property
private User user;
@Property
private Skill skill;
public Block getAddSkillsBlock() {
return addSkillsBlock;
}
public Zone getUserSkillsZone() {
return userSkillsZone;
}
public List<Skill> getSkills() {
return skillManager.findAll();
}
public List<Skill> getUserSkills() {
return new ArrayList<Skill>(user.getSkills());
}
public void onActivate(Integer id) {
user = userManager.findById(id);
}
public Integer onPassivate() {
return user.getUserId();
}
public Block onActionFromAddSkills() {
return addSkillsBlock;
}
public void onActionFromHideSkills() {
}
public Zone onActionFromAddSkill(Integer skillId) {
user.addSkill(skillManager.findById(skillId));
userManager.persist(user);
return userSkillsZone;
}
public Zone onActionFromDeleteSkill(Integer skillId) {
return onActionFromDeleteUserSkill(skillId);
}
public Zone onActionFromDeleteUserSkill(Integer skillId) {
user.removeSkill(skillManager.findById(skillId));
userManager.persist(user);
return userSkillsZone;
}
}Nous notons l'injection des composants addSkillsBlock et userSkillsZone.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<title>Skills for ${user.fullname}</title>
</head>
<body>
<h1>Skills for ${user.fullname}</h1>
<!-- Using a block that will not load all skills in the page until the actionlink addSkills is clicked -->
<t:block t:id="addSkillsBlock">
<fieldset xmlns="http://www.w3.org/1999/xhtml">
<t:loop source="skills" value="skill">
<t:actionlink t:id="addSkill" t:zone="userSkillsZone" context="skill.skillId">${skill.name}</t:actionlink>
</t:loop>
<div style="text-align: right;"><t:actionlink t:id="hideSkills">Hide</t:actionlink></div>
</fieldset>
</t:block>
<t:zone t:id="addSkillsZone" />
<t:zone t:id="userSkillsZone">
<ul xmlns="http://www.w3.org/1999/xhtml">
<li t:type="loop" t:source="userSkills" t:value="skill">
${skill.name}
- <t:actionlink t:id="deleteUserSkill" t:zone="userSkillsZone" context="skill.skillId">Delete</t:actionlink>
</li>
</ul>
</t:zone>
<p>
<t:actionlink t:id="addSkills" t:zone="addSkillsZone">Add skills</t:actionlink>
</p>
<p>
<t:pagelink page="users/Index">Back</t:pagelink>
</p>
</body>
</html>Examinons tout d'abord l'affichage des compétences après le clic sur l'actionlink addSkills. On remarque l'attribut t:zone sur l'actionlink, il indique l'identifiant de la zone de la page qui recevra la réponse du clic sur l'actionlink. La méthode Java correspondante est, toujours par convention onActionFromAddSkills. Comme nous pouvons le voir, cette méthode retourne un block. Le block retourné est addSkillsBlock, un composant de notre page tml injecté dans notre classe Java. Il correspond donc au block d'identifiant addSkillsBlock. Ce block va afficher toutes les compétences listées par la variable skills et donc par la méthode getSkills de la classe Java.
Chaque compétence est encadrée par un actionlink qui permettra de rajouter cette compétence à l'utilisateur. De la même manière ces actionlink ont un attribut t:zone qui référence userSkillsZone. Cela permettra de recharger la liste des compétences de l'utilisateur une fois une compétence ajoutée.
VIII. Remerciements▲
Merci à Matthieu LuxMatthieu Lux pour sa participation sur la partie Maven ainsi qu'à RideKickRideKick pour sa relecture.